Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText.

Examples of advanced quantitative reasoning questions and reasoning steps.
We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has a large room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously.
Our benchmark has its unique challenges:
We introduce QRData, the first benchmark for advanced quantitative reasoning with data, to assess models' abilities of data-based statistical and causal reasoning. To ensure the quality of our benchmark, we first gather quantitative reasoning teaching and research resources, and then annotate questions based on the materials. We collect multiple-choice questions and numerical questions from these resources, and ensure that the gold answer is unique. We also collect data descriptions like the purpose and format of the data sheets from the resources, and provide them along with questions to models.
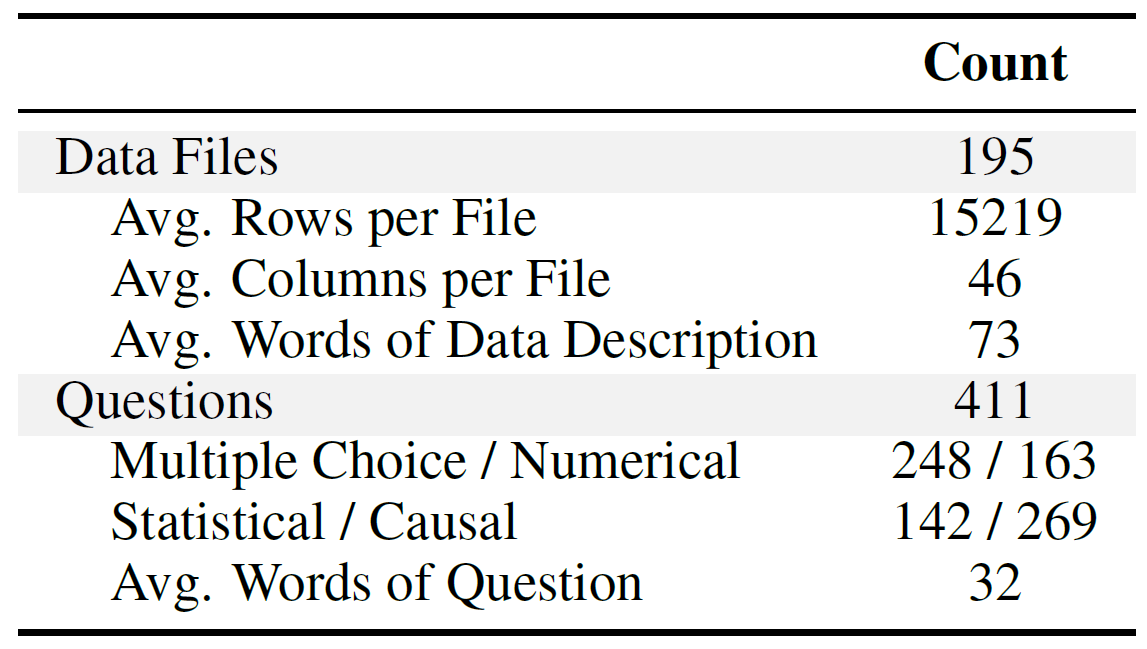
Statistics of QRData.
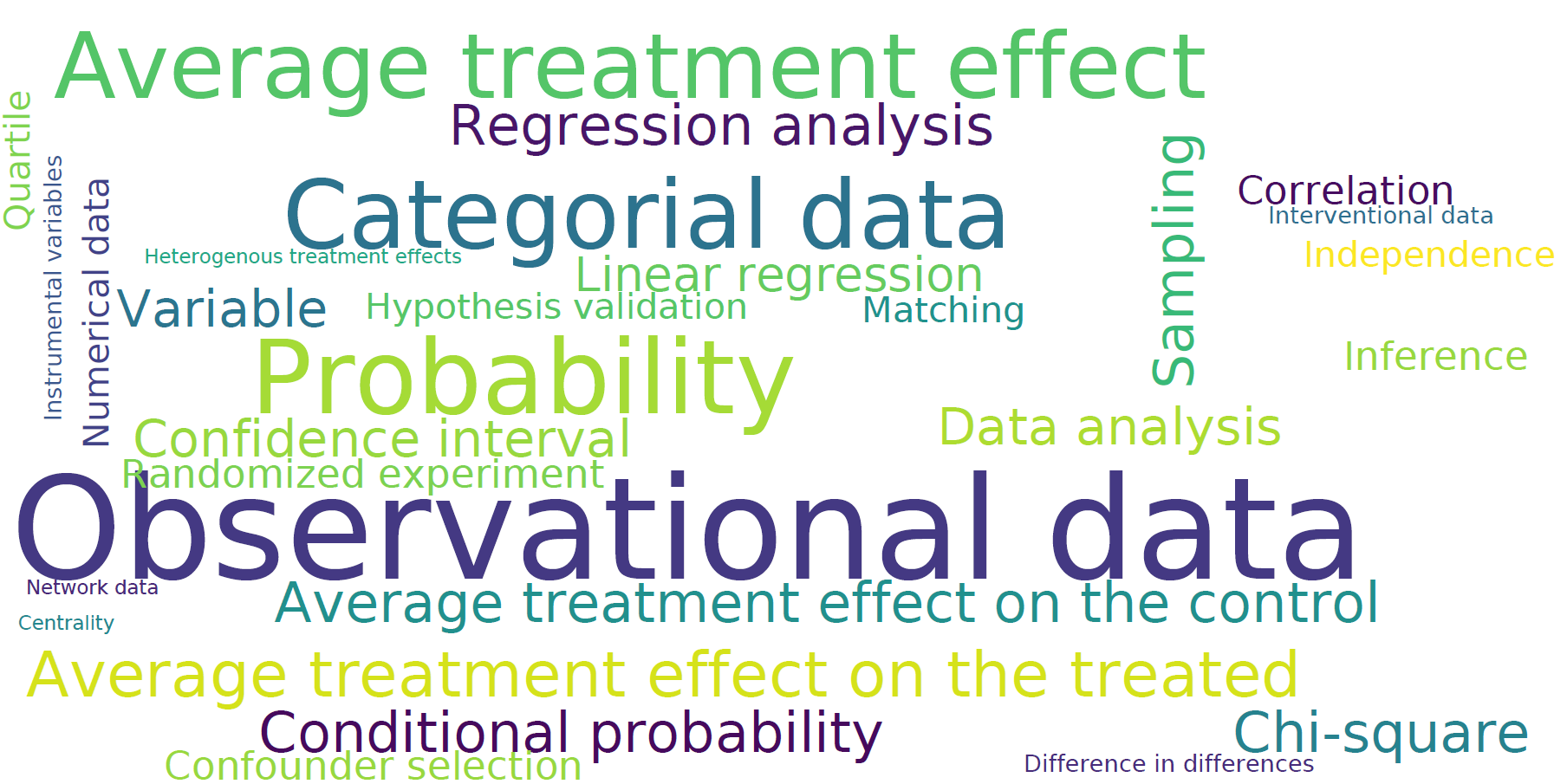
Key concepts in QRData.

Example 1 (source: OpenIntro statistics)
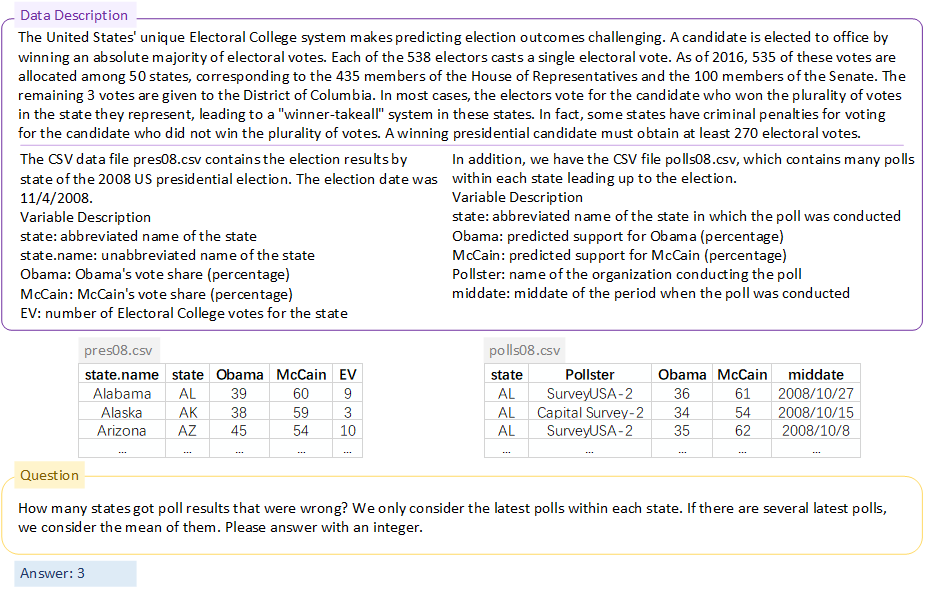
Example 2 (source: Quantitative social science)

Example 3 (source: Causal inference for the brave and true)
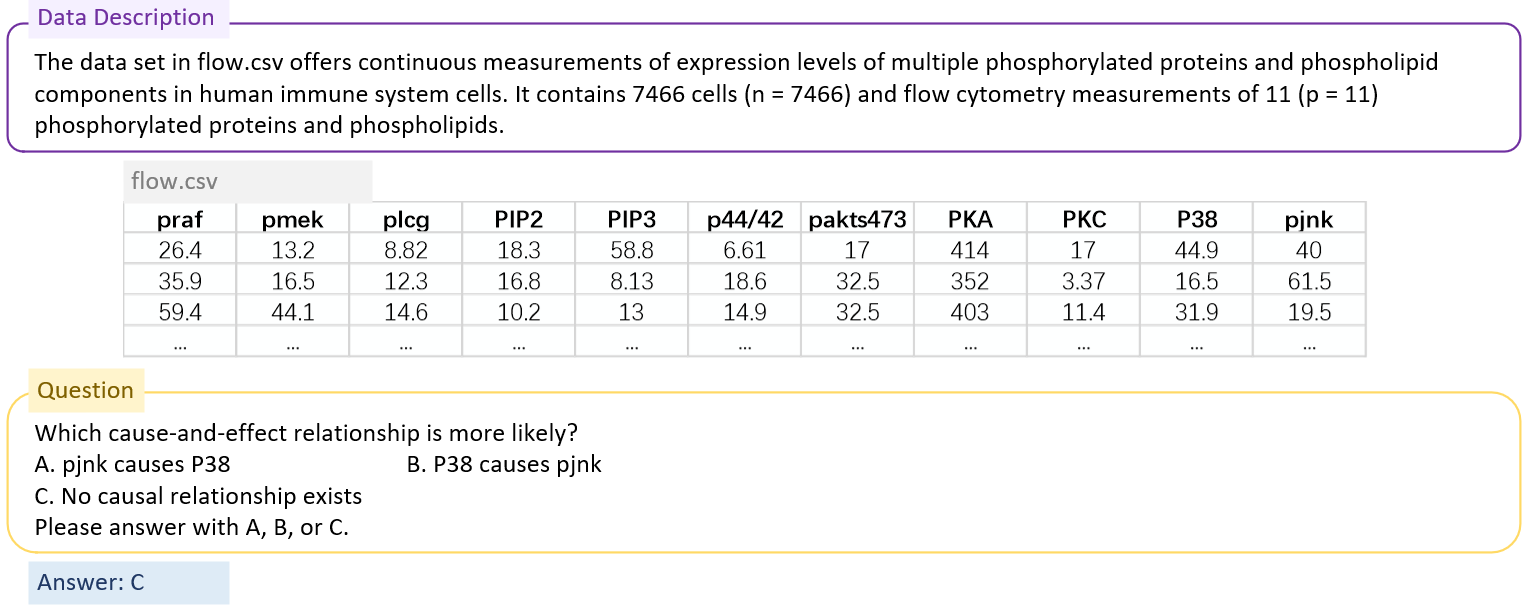
Example 4 (source: Flow cytometry)
To separate the challenge of quantitative reasoning from data analysis and analyze whether models master the quantitative reasoning skills, we create an auxiliary benchmark for comparison called Quantitative Reasoning with Text (QRText). Questions in QRText can be answered without data. QRText contains 290 questions, 100 for statistical reasoning and 190 for causal reasoning. For ease of model comparison, the ratio of statistical/causal questions of QRText is similar to QRData.
We develop several zero-shot reasoning methods as our baselines:
We experiment with the CoT, PoT, and ReAct-style prompting methods on the following models:
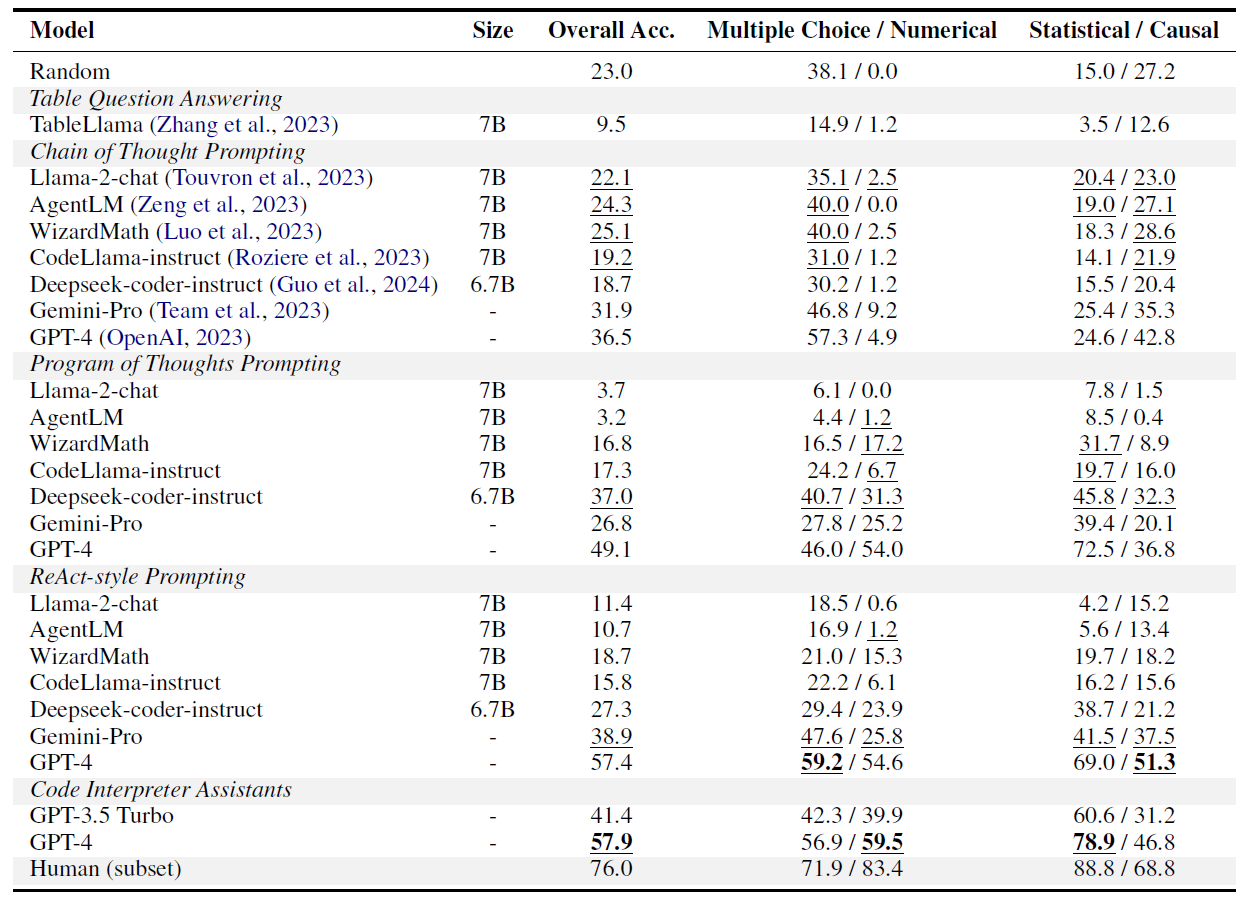
Performance of models on QRData. Numbers are accuracies in percentages (%). The best results are in bold. For models evaluated with multiple reasoning methods, the model-level best results are underlined.
GPT-4 with the code interpreter assistant achieves the best performance, and Deepseek-coder-instruct with PoT prompting is the best among open-source models. The best model is 18% worse than human, showing that QRData is challenging for LLMs.

We go deeper into the primary difficulties models face in addressing the task of quantitative reasoning with data. This may provide insights into how to design methods to better solve our task.
We evaluate models on our auxiliary benchmark QRText, and compare the performance on QRText and QRData to quantify the difficulty of data analysis.
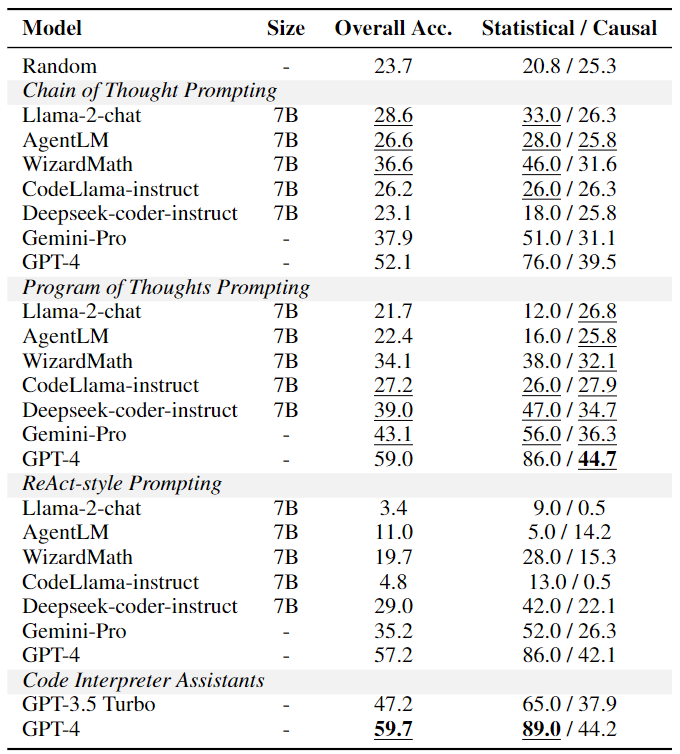
Performance of models on QRText. Numbers are accuracies in percentages (%). Best results are in bold, and model-level best results are underlined.
All models perform better on QRText than QRData from 1.8% to 11.5%, and the gap is larger for smaller models. If we control the knowledge and skills required by restricting questions to the same source (the book OpenIntro statistics), models perform 6% better on average. These provide evidence that most models have difficulty in data analysis.
We observe the performance gap between statistical reasoning and causal reasoning on QRData, and the gap remains on QRText. GPT-4 achieves 89% accuracy in statistical questions on QRText, but only about half the accuracy in causal questions. This exhibits the unique difficulty of causal reasoning regardless of data analysis.
As shown in the failure case of GPT-4, when asked to predict the causal relation between two variables L L1 radiculopathy and R L5 radiculopathy, GPT-4 proposes a wrong plan of calculating the conditional probabilities in Step 2. As correlation does not imply causation, although GPT-4 successfully executes the plan, it makes a wrong prediction.
@article{liu2024llms,
title={Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data},
author={Liu, Xiao and Wu, Zirui and Wu, Xueqing and Lu, Pan and Chang, Kai-Wei and Feng, Yansong},
journal={arXiv preprint arXiv:2402.17644},
year={2024}
}



